2026
Large-Scale Universal Defect Generation: Foundation Models and Datasets
Yuanting Fan, Jun Liu, Bin-Bin Gao, Xiaochen Chen, Yuhuan Lin, Zhewei Dai, Jiawei Zhan, Chengjie Wang
Preprint, arXiv 2026
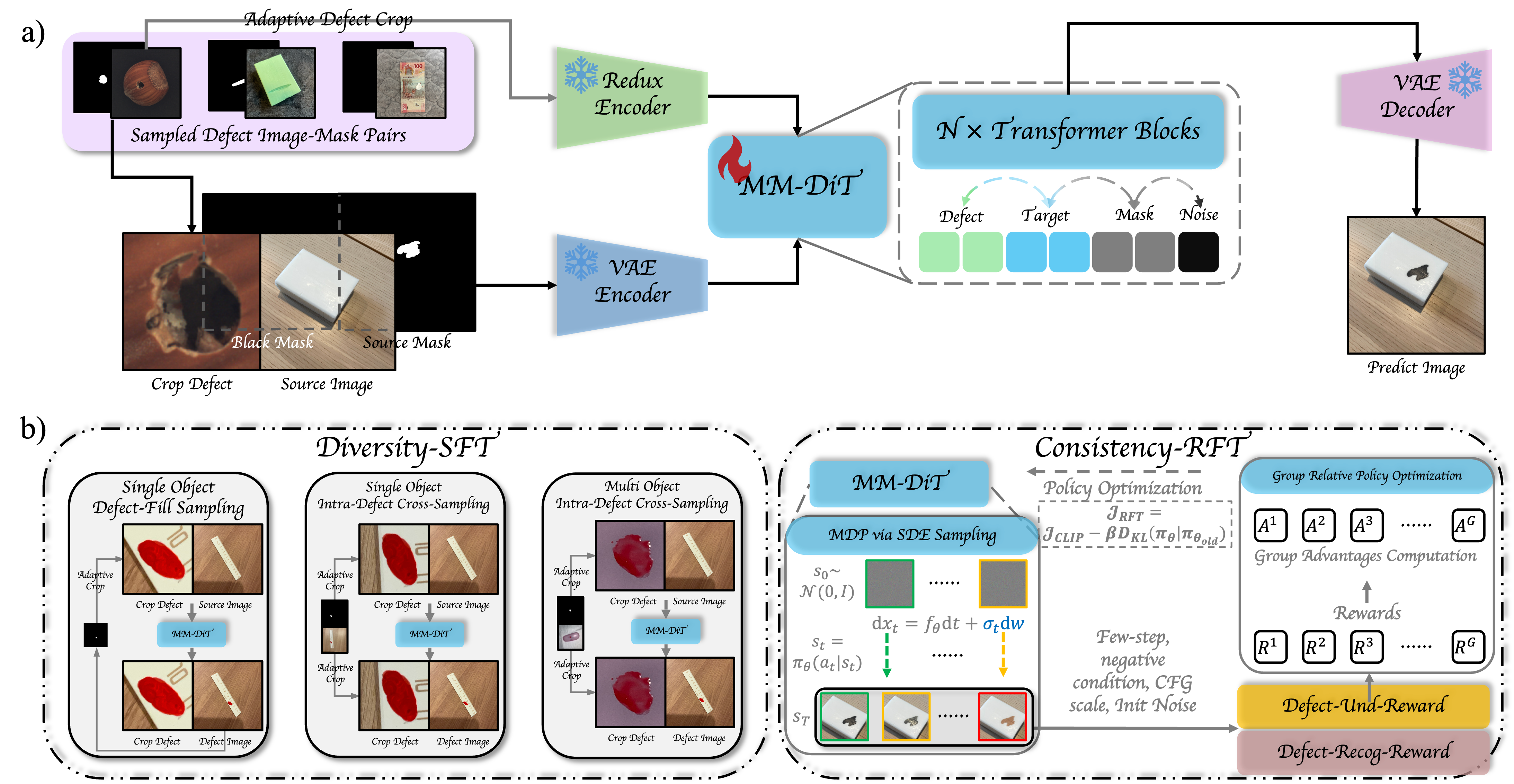
Existing defect/anomaly generation methods often rely on few-shot learning, which overfits to specific defect categories due to the lack of large-scale paired defect editing data. This issue is aggravated by substantial variations in defect scale and morphology, resulting in limited generalization, degraded realism, and category consistency. We address these challenges by introducing UDG, a large-scale dataset of 300K normal-abnormal-mask-caption quadruplets spanning diverse domains, and by presenting UniDG, a universal defect generation foundation model that supports both reference-based defect generation and text instruction-based defect editing without per-category fine-tuning. UniDG performs Defect-Context Editing via adaptive defect cropping and structured diptych input format, and fuses reference and target conditions through MM-DiT multimodal attention. A two-stage training strategy, Diversity-SFT followed by Consistency-RFT, further improves diversity while enhancing realism and reference consistency. Extensive experiments on MVTec-AD and VisA show that UniDG outperforms prior few-shot anomaly generation and image insertion/editing baselines in synthesis quality and downstream single- and multi-class anomaly detection/localization.
Large-Scale Universal Defect Generation: Foundation Models and Datasets
Yuanting Fan, Jun Liu, Bin-Bin Gao, Xiaochen Chen, Yuhuan Lin, Zhewei Dai, Jiawei Zhan, Chengjie Wang
Preprint, arXiv 2026
Existing defect/anomaly generation methods often rely on few-shot learning, which overfits to specific defect categories due to the lack of large-scale paired defect editing data. This issue is aggravated by substantial variations in defect scale and morphology, resulting in limited generalization, degraded realism, and category consistency. We address these challenges by introducing UDG, a large-scale dataset of 300K normal-abnormal-mask-caption quadruplets spanning diverse domains, and by presenting UniDG, a universal defect generation foundation model that supports both reference-based defect generation and text instruction-based defect editing without per-category fine-tuning. UniDG performs Defect-Context Editing via adaptive defect cropping and structured diptych input format, and fuses reference and target conditions through MM-DiT multimodal attention. A two-stage training strategy, Diversity-SFT followed by Consistency-RFT, further improves diversity while enhancing realism and reference consistency. Extensive experiments on MVTec-AD and VisA show that UniDG outperforms prior few-shot anomaly generation and image insertion/editing baselines in synthesis quality and downstream single- and multi-class anomaly detection/localization.
Towards Fine-Grained Vision-Language Alignment for Few-Shot Anomaly Detection
Yuanting Fan, Jun Liu, Xiaochen Chen, Bin-Bin Gao, Jian Li, Yong Liu, Jinlong Peng, Chengjie Wang
Pattern Recognition 2026
Few-shot anomaly detection (FSAD) methods identify anomalous regions with few known normal samples. Most existing methods rely on the generalization ability of pre-trained vision-language models (VLMs) to recognize potentially anomalous regions through feature similarity between text descriptions and images. However, due to the lack of detailed textual descriptions, these methods can only pre-define image-level descriptions to match each visual patch token to identify potential anomalous regions, which leads to the semantic misalignment between image descriptions and patch-level visual anomalies, achieving sub-optimal localization performance. To address the above issues, we propose the Multi-Level Fine-Grained Semantic Caption (MFSC) to provide multi-level and fine-grained textual descriptions for existing anomaly detection datasets with automatic construction pipeline. Based on the MFSC, we propose a novel framework named FineGrainedAD to improve anomaly localization performance, which consists of two components: Multi-Level Learnable Prompt (MLLP) and Multi-Level Semantic Alignment (MLSA). MLLP introduces fine-grained semantics into multi-level learnable prompts through automatic replacement and concatenation mechanism, while MLSA designs region aggregation strategy and multi-level alignment training to facilitate learnable prompts better align with corresponding visual regions. Experiments demonstrate that the proposed FineGrainedAD achieves superior overall performance in few-shot settings on MVTec-AD and VisA datasets.
Towards Fine-Grained Vision-Language Alignment for Few-Shot Anomaly Detection
Yuanting Fan, Jun Liu, Xiaochen Chen, Bin-Bin Gao, Jian Li, Yong Liu, Jinlong Peng, Chengjie Wang
Pattern Recognition 2026
Few-shot anomaly detection (FSAD) methods identify anomalous regions with few known normal samples. Most existing methods rely on the generalization ability of pre-trained vision-language models (VLMs) to recognize potentially anomalous regions through feature similarity between text descriptions and images. However, due to the lack of detailed textual descriptions, these methods can only pre-define image-level descriptions to match each visual patch token to identify potential anomalous regions, which leads to the semantic misalignment between image descriptions and patch-level visual anomalies, achieving sub-optimal localization performance. To address the above issues, we propose the Multi-Level Fine-Grained Semantic Caption (MFSC) to provide multi-level and fine-grained textual descriptions for existing anomaly detection datasets with automatic construction pipeline. Based on the MFSC, we propose a novel framework named FineGrainedAD to improve anomaly localization performance, which consists of two components: Multi-Level Learnable Prompt (MLLP) and Multi-Level Semantic Alignment (MLSA). MLLP introduces fine-grained semantics into multi-level learnable prompts through automatic replacement and concatenation mechanism, while MLSA designs region aggregation strategy and multi-level alignment training to facilitate learnable prompts better align with corresponding visual regions. Experiments demonstrate that the proposed FineGrainedAD achieves superior overall performance in few-shot settings on MVTec-AD and VisA datasets.
2024
InstanceSR: Efficient Reconstructing Small Object with Differential Instance-level Super-Resolution
Yuanting Fan, Chengxu Liu, Ruhao Tian, Xueming Qian
IEEE TCSVT2025 2024
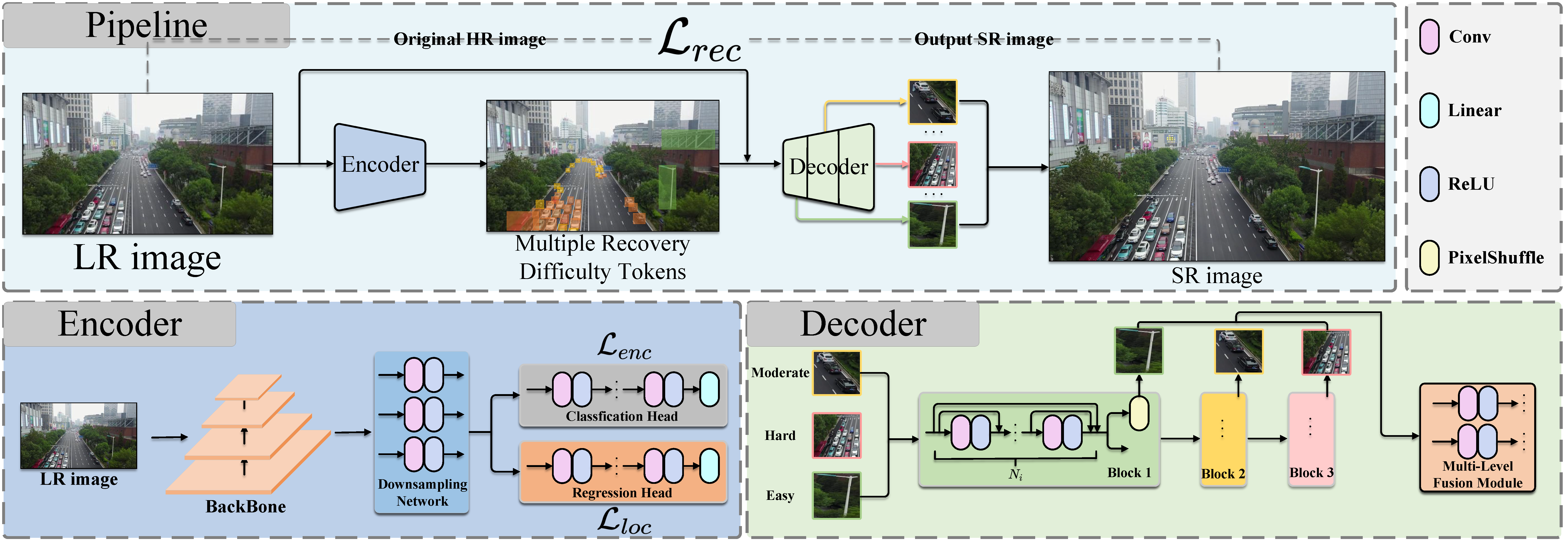
Super-resolution (SR) aims to restore a high-resolution (HR) image from its low-resolution (LR) counterpart. Existing works try to achieve an overall average recovery over all regions to provide better visual quality for human viewing. If we desire to explore the potential that performs super-resolution for machine recognition instead of human viewing, the solution should change accordingly. From this insight, we propose a new SR pipeline, called InstanceSR, which treats each region in the LR image differentially and consumes more resources to focus on the recovery of the foreground region where the instances exist. In particular, InstanceSR consists of an encoder that formulates the LR image into a set of various difficulty tokens according to the instances distribution in each sub-region, and a decoder based on a multi-exit network structure to recover the sub-regions corresponding to various difficulty tokens by consuming different computational resources. Experimental results demonstrate the superiority of the proposed InstanceSR over state-of-the-art models, especially the recovery of regions where instances exist, by extensive quantitative and qualitative evaluations on three widely used benchmarks containing small instances. Besides, the comparisons using SR results on three challenging small object detection benchmarks verify that our InstanceSR can consistently boost the detection accuracy and has great potential for subsequent machine recognition.
InstanceSR: Efficient Reconstructing Small Object with Differential Instance-level Super-Resolution
Yuanting Fan, Chengxu Liu, Ruhao Tian, Xueming Qian
IEEE TCSVT2025 2024
Super-resolution (SR) aims to restore a high-resolution (HR) image from its low-resolution (LR) counterpart. Existing works try to achieve an overall average recovery over all regions to provide better visual quality for human viewing. If we desire to explore the potential that performs super-resolution for machine recognition instead of human viewing, the solution should change accordingly. From this insight, we propose a new SR pipeline, called InstanceSR, which treats each region in the LR image differentially and consumes more resources to focus on the recovery of the foreground region where the instances exist. In particular, InstanceSR consists of an encoder that formulates the LR image into a set of various difficulty tokens according to the instances distribution in each sub-region, and a decoder based on a multi-exit network structure to recover the sub-regions corresponding to various difficulty tokens by consuming different computational resources. Experimental results demonstrate the superiority of the proposed InstanceSR over state-of-the-art models, especially the recovery of regions where instances exist, by extensive quantitative and qualitative evaluations on three widely used benchmarks containing small instances. Besides, the comparisons using SR results on three challenging small object detection benchmarks verify that our InstanceSR can consistently boost the detection accuracy and has great potential for subsequent machine recognition.
AdaDiffSR: Adaptive Region-aware Dynamic Acceleration Diffusion Model for Real-World Image Super-Resolution
Yuanting Fan, Chengxu Liu, Nengzhong Yin, Changlong Gao, Xueming Qian
ECCV2024 2024
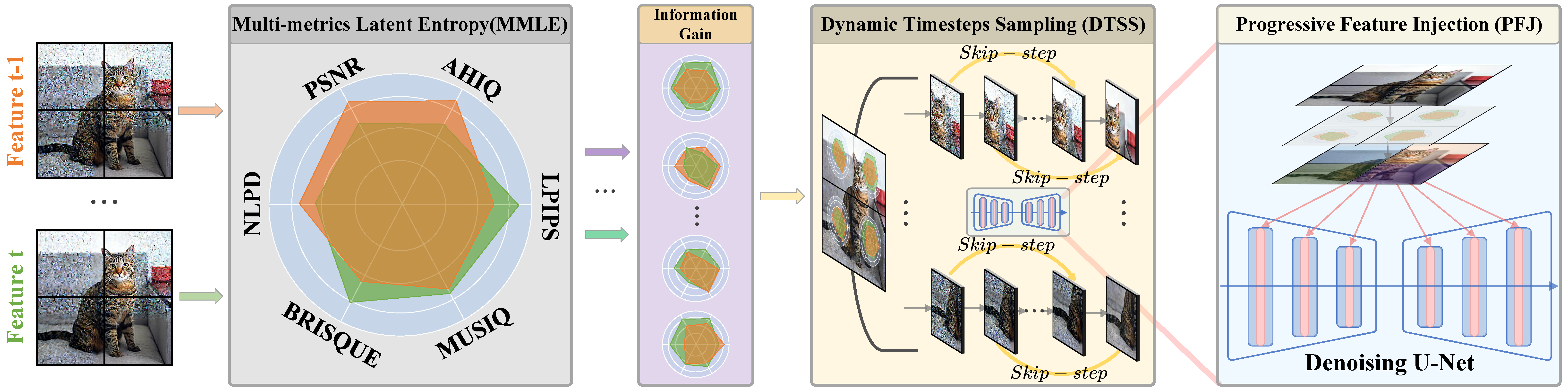
Diffusion models (DMs) have shown promising results on single-image super-resolution and other image-to-image translation tasks. Benefiting from more computational resources and longer inference times, they are able to yield more realistic imagesqueryThis is to inform you that corresponding author has been identified as per the information available in the Copyright form.. Existing DMs-based super-resolution methods try to achieve an overall average recovery over all regions via iterative refinement, ignoring the consideration that different input image regions require different timesteps to reconstruct. In this work, we notice that previous DMs-based super-resolution methods suffer from wasting computational resources to reconstruct invisible details. To further improve the utilization of computational resources, we propose AdaDiffSR, a DMs-based SR pipeline with dynamic timesteps sampling strategy (DTSS). Specifically, by introducing the multi-metrics latent entropy module (MMLE), we can achieve dynamic perception of the latent spatial information gain during the denoising process, thereby guiding the dynamic selection of the timesteps. In addition, we adopt a progressive feature injection module (PFJ), which dynamically injects the original image features into the denoising process based on the current information gain, so as to generate images with both fidelity and realism. Experiments show that our AdaDiffSR achieves comparable performance over current state-of-the-art DMs-based SR methods while consuming less computational resources and inference time on both synthetic and real-world datasets.
AdaDiffSR: Adaptive Region-aware Dynamic Acceleration Diffusion Model for Real-World Image Super-Resolution
Yuanting Fan, Chengxu Liu, Nengzhong Yin, Changlong Gao, Xueming Qian
ECCV2024 2024
Diffusion models (DMs) have shown promising results on single-image super-resolution and other image-to-image translation tasks. Benefiting from more computational resources and longer inference times, they are able to yield more realistic imagesqueryThis is to inform you that corresponding author has been identified as per the information available in the Copyright form.. Existing DMs-based super-resolution methods try to achieve an overall average recovery over all regions via iterative refinement, ignoring the consideration that different input image regions require different timesteps to reconstruct. In this work, we notice that previous DMs-based super-resolution methods suffer from wasting computational resources to reconstruct invisible details. To further improve the utilization of computational resources, we propose AdaDiffSR, a DMs-based SR pipeline with dynamic timesteps sampling strategy (DTSS). Specifically, by introducing the multi-metrics latent entropy module (MMLE), we can achieve dynamic perception of the latent spatial information gain during the denoising process, thereby guiding the dynamic selection of the timesteps. In addition, we adopt a progressive feature injection module (PFJ), which dynamically injects the original image features into the denoising process based on the current information gain, so as to generate images with both fidelity and realism. Experiments show that our AdaDiffSR achieves comparable performance over current state-of-the-art DMs-based SR methods while consuming less computational resources and inference time on both synthetic and real-world datasets.
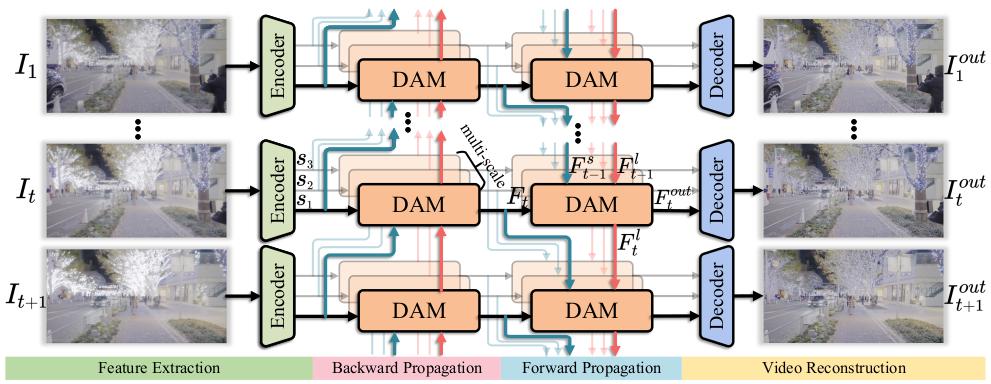
Decoupling degradations with recurrent network for video restoration in under-display camera
Chengxu Liu, Xuan Wang, Yuanting Fan, Shuai Li, Xueming Qian
AAAI2024 2024
Under-display camera (UDC) systems are the foundation of full-screen display devices in which the lens mounts under the display. The pixel array of light-emitting diodes used for display diffracts and attenuates incident light, causing various degradations as the light intensity changes. Unlike general video restoration which recovers video by treating different degradation factors equally, video restoration for UDC systems is more challenging that concerns removing diverse degradation over time while preserving temporal consistency. In this paper, we introduce a novel video restoration network, called D2RNet, specifically designed for UDC systems. It employs a set of Decoupling Attention Modules (DAM) that effectively separate the various video degradation factors. More specifically, a soft mask generation function is proposed to formulate each frame into flare and haze based on the diffraction arising from incident light of different intensities, followed by the proposed flare and haze removal components that leverage long- and short-term feature learning to handle the respective degradations. Such a design offers an targeted and effective solution to eliminating various types of degradation in UDC systems. We further extend our design into multi-scale to overcome the scale-changing of degradation that often occur in long-range videos. To demonstrate the superiority of D2RNet, we propose a large-scale UDC video benchmark by gathering HDR videos and generating realistically degraded videos using the point spread function measured by a commercial UDC system. Extensive quantitative and qualitative evaluations demonstrate the superiority of D2RNet compared to other state-of-the-art video restoration and UDC image restoration methods.
Decoupling degradations with recurrent network for video restoration in under-display camera
Chengxu Liu, Xuan Wang, Yuanting Fan, Shuai Li, Xueming Qian
AAAI2024 2024
Under-display camera (UDC) systems are the foundation of full-screen display devices in which the lens mounts under the display. The pixel array of light-emitting diodes used for display diffracts and attenuates incident light, causing various degradations as the light intensity changes. Unlike general video restoration which recovers video by treating different degradation factors equally, video restoration for UDC systems is more challenging that concerns removing diverse degradation over time while preserving temporal consistency. In this paper, we introduce a novel video restoration network, called D2RNet, specifically designed for UDC systems. It employs a set of Decoupling Attention Modules (DAM) that effectively separate the various video degradation factors. More specifically, a soft mask generation function is proposed to formulate each frame into flare and haze based on the diffraction arising from incident light of different intensities, followed by the proposed flare and haze removal components that leverage long- and short-term feature learning to handle the respective degradations. Such a design offers an targeted and effective solution to eliminating various types of degradation in UDC systems. We further extend our design into multi-scale to overcome the scale-changing of degradation that often occur in long-range videos. To demonstrate the superiority of D2RNet, we propose a large-scale UDC video benchmark by gathering HDR videos and generating realistically degraded videos using the point spread function measured by a commercial UDC system. Extensive quantitative and qualitative evaluations demonstrate the superiority of D2RNet compared to other state-of-the-art video restoration and UDC image restoration methods.